基于识别时间窗中的数据包定时异常检测汽车CAN网络攻击
2018 48th Annual IEEE/IFIP International Conference on Dependable Systems and Networks Workshops
本文主要介绍一定时间窗口内的CAN数据包的序列异常来识别网络攻击,提出了一种分析CAN广播和随后的测试统计方法来检测时间变化的CAN流量指示一些预测的攻击。检测是在时间定义的窗口中实现的。
基本概念
CAN总线:CAN是控制器局域网络(Controller Area Network, CAN)的简称,是由以研发和生产汽车电子产品著称的德国BOSCH公司开发的,并最终成为国际标准(ISO 11898),是国际上应用最广泛的现场总线之一。 在北美和西欧,CAN总线协议已经成为汽车计算机控制系统和嵌入式工业控制局域网的标准总线,并且拥有以CAN为底层协议专为大型货车和重工机械车辆设计的J 1939协议。
-
串行通信协议
-
通信速率最高可达 1Mbps
-
通信数据的成帧处理
-
网络内的节点个数理论上不受限制
-
各节点之间可以自由通信:多主竞争总线结构
-
结构简单
没有消息确认、发送方身份验证、加密
存在的问题:
-
注入包含恶意数据的CAN数据包:CAN Message InjectionOG Dynamite Edition
-
强制刷新ECU注入恶意代码:Experimental Security Analysis of a Modern Automobile
CAN数据包:
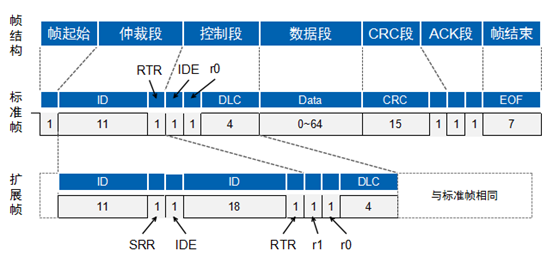
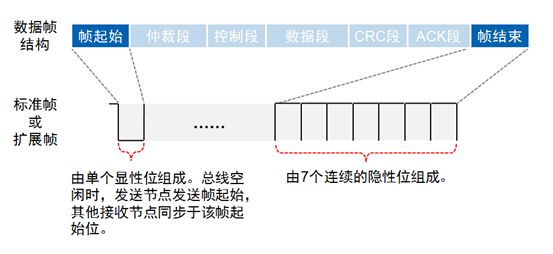
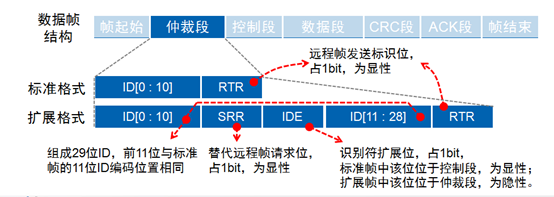
帧ID越小,优先级越高。由于数据帧的RTR位为显性电平,远程帧为隐性电平,所以帧格式和帧ID相同的情况下,数据帧优先于远程帧;由于标准帧的IDE位为显性电平,扩展帧的IDE位为隐形电平,对于前11位ID相同的标准帧和扩展帧,标准帧优先级比扩展帧高。
存在的问题
IDS 入侵检测系统
开发一个CAN IDS的挑战之一是,CAN消息是专有的,不同的汽车制造和型号均不相同。因此,虽然CAN协议公开发布,但消息标识符、数据含义和广播的时间并没有被制造商披露,而且不能假定在一系列汽车制造商和模型中是相似的。因此,一个可行的CAN IDS需要易于配置,以适应如此广泛的范围。
CAN数据包是由ecu创建的,由包含CAN ID的仲裁字段和其他字段(包括数据字段)组成。CAN id通常被认为是每个ecu的唯一标识,并被其他ecu用来决定数据包是否与它们相关。CAN仲裁过程定义了CAN ID值越低,报文的优先级越高。如果多个ECU同时尝试广播报文,则广播CAN ID值最小的报文的ECU将成功。
CAN数据包,特别是那些更重要的数据包,通常以非常规则、频繁的周期、进行广播。因此,CAN id重复出现的频率可以提供一种检测某些攻击的方法。这里关注的攻击模式(刷新和包注入)可能会强制临时改变相关CAN包、、的广播频率。在刷新攻击中,来自ECU的数据包在刷新时不会广播,从而导致相关CAN id的暂时减少。在注入攻击中,某些CAN id的广播频率会增加,因为攻击要求以足够高的速率广播虚假数据包,以淹没相关的合法广播。另外,CAN仲裁过程(CAN ID值越低,广播优先级越高)可能会导致某些CAN ID的广播槽丢失给攻击中使用的优先级较高的占主导地位的CAN ID。
-
重新刷新攻击:某些数据包不会出现,相关的CAN ID在一定时间窗口内不会出现
-
注入攻击: 某些数据包在一定的时间窗口内会出现高频率传输,攻击要求以足够高的速率广播虚假数据包,以淹没相关的合法广播
时间窗口的方法
时间定义窗口方法将数据处理为离散窗口。将计算出的指标和随后的决策保持在窗口的本地,可以减少数据中反映的任何长期系统更改的影响。有一些窗口方法可以用于数据包定时异常检测。一种选择是处理窗口以获得度量,然后应用这些度量对下一个广播进行分类。窗口一次滑过一个广播的数据,在每个广播重新计算指标。
在本研究中,我们在离散的、不重叠的、连续的窗口中处理数据,其优点是减少度量的重新计算;在有限的CPU容量的车辆有利。在我们的研究中,对一个窗口的指标进行计算,然后应用到该窗口内的所有广播进行分类,然后评估下一个不重叠的窗口。与滑动窗口相比,这种方法减少了窗口指标需要重新计算的频率。根据窗口中的广播评估指标可以确保评估的广播在检测方法捕获的任何自然发生的调整的范围内。它还确保在旅程一开始就对异常情况进行评估。
我们将时间窗方法与两种无监督方法(z分数和自回归综合移动平均法)相结合;以及用监督方法(与平均广播间隔比较)进行比较。这些内容载于第四- b节。使用z分数和基于时间的数据的ARIMA已被证明可以结合来自各种来源的数据,以评估复杂计算机网络受到攻击的可能性。尽管这些方法需要一个阈值分数来优化检测,但它们在适应数据集之间的方差和差异方面需要很少的监督,不需要训练干预。因此,它们可能提供有用的方法来检测CAN ID广播频率的变化,考虑到CAN操作的未知和不同的汽车。
z-score: Z-Score标准化是数据处理的一种常用方法。通过它能够将不同量级的数据转化为统一量度的Z-Score分值进行比较。
ARIMA: AutoRegressive Integrated Moving Average(差分自回归移动平均模型)
差分整合移动平均自回归模型,又称整合移动平均自回归模型(移动也可称作滑动),是时间序列预测分析方法之一
ARIMA里面的I指Integrated(差分)。 ARIMA(p,d,q)就表示p阶AR,d次差分,q阶MA。 为什么要进行差分呢? ARIMA的前提是数据是stationary的,也就是说统计特性(mean,variance,correlation等)不会随着时间窗口的不同而变化。
研究步骤
对一辆汽车进行初始CAN分析,以建立其CAN广播的速率和一致性,并建立监督检测方法中使用的阈值。
-
数据捕获 Kvaser Leaf Light
-
播放率
55个CAN id被检测到,其中只有两个在整个旅程中被广播。在一段旅程开始时,两个id短暂出现,之后再没有被发现。这些被排除在随后的测试之外。
一般来说,优先级越高(即ID值越低)的CAN ID广播频率越高,时间变化越小。图1和图2显示了CAN ID匹配数据包的每秒平均广播次数和广播间隔时间。由于广播频率和时间的模式是相似的旅程,只有一个旅程显示。大多数数据包的广播间隔是一致的。优先级越高的CAN id的广播频率越高,有的广播速度约为每秒100个,而只有4个CAN id的广播速度小于每秒10个(图1)。
大多数CAN ID的广播间隔变化都很小(图2)。除了一个ID外,其他所有ID的最大重复广播时差都小于0.1秒,其中39个ID(71%)的最大重复广播时差小于0.01秒。40个CAN id的重复广播标准偏差小于0.0007秒,而除4个外,其他所有的标准偏差小于0.01秒。
总体而言,分析表明ecu在整个航程和每次航程中都以一致的、可预测的速度广播其信息。其他研究人员在分析其他汽车时注意到CAN信息广播的这种一致性。如果我们假设单个CAN id是特定于单个ecu的,那么几乎所有广播ecu将以每秒10次或更多的频率广播,大多数广播以每秒100次以上的一致速度广播。
这种观察到的CAN识别广播的规律性,在不同的汽车制造和型号中显示出来,提出了这样一个问题,即广播的规律性是否足以使人们容易发现可能意味着攻击的变化,特别是在第二- a节中概述的那些变化
A.攻击仿真
通过系统地更新行程中的CAN日志副本,对每个CAN ID进行攻击模拟。修改后的日志文件通过我们的检测算法进行处理。Taylor等人使用了类似的方法、Marchetti和Stabili,试图模拟Miller和Valasek[5][15]演示的真实攻击对CAN流量的影响。
捕获的日志以两种方式进行更改,以生成两个测试集:丢弃包和注入包。
述两种攻击类型中的任何一种都可能导致数据包丢失(参见第II-A节)。在一次刷新攻击中,被攻击ECU的固件被攻击向量覆盖,从而被适配的固件取代。关于广播计时的变化,ECU将错过广播,否则在刷新期间会发生。由于CAN仲裁过程导致的广播丢失的增加也可能是由注入攻击触发的,当一个更高优先级的携带恶意数据的ID被高速广播,以确保恶意数据的广播超过合法数据。因此,丢弃广播检测的目的是看看这些方法是否能够检测到数据包广播已经被跳过。
当被破坏或非法添加的ECU广播数据包模仿合法ECU的数据包时,可能会发生,从而广播错误的数据或错误的控制信号。这种攻击的另一种变体是拒绝服务攻击,在这种攻击中,数据包以快速的频率提交,以压倒总线。Miller和V alasek[5]已经证明了CAN注入攻击。因此,注入攻击检测的目的是看看这些方法是否能够检测到插入了额外的数据包广播。
对于每次攻击,在整个日志期间随机选择时间点,在捕获的日志文件中创建20个攻击点。对于丢弃广播模拟,与被测试ID相关的数据包在随机分配的攻击点被移除一秒。对于注入检测,在随机选择的时间后的下一个可用间隙插入一个相关CAN ID的广播到日志文件中,注入广播的时间戳集相应。
然后通过将日志按时间顺序提交给检测算法来评估日志,从而模拟生产执行中可能发生的现场广播的处理。
CAN数据流被处理为离散的、连续的固定时间的窗口,例如1秒。在完成每个窗口的广播后,将该窗口内特定CAN ID的平均广播间隔与该窗口内的每个CAN ID广播进行比较。因此,对于窗口内的每个广播Biof CAN ID,从Bi−1开始计算时间间隔,并与窗口内的CAN ID的平均值进行比较。比较方法说明如下。完成后,分析将移到下一个窗口。
B. 方法测试
比较三种检测方法:
-
用于基于均方误差的广播间隔异常检测(无监督)的窗口的 ARIMA 模型。
-
每个广播间隔的 Z 分数与窗口平均值(无监督)进行比较。
-
广播时间间隔与窗口均值(监督)的比较。
在这个窗口上下文中使用[21]和[22]中讨论的前两个方法时,可以认为是无监督的,因为在窗口和CAN id之间的任何差异都会被缩放成相似的大小。这可以方便指定一个共同的阈值,而不需要根据不同汽车或情况的CAN行为差异进行调整。
第三种方法(广播间隔与窗口均值的比较)作为基线,用于与其他两种方法的比较。这种方法应该表现最好,因为它使用了一个根据一组训练数据行程的广播之间观察到的差异量身定制的阈值。上述分析建议测试阈值为0.003秒左右,我们的汽车制造和型号。
测试在R中实现,使用auto.Arima和scale()函数。auto。Arima函数设计用于快速、自动估计时间序列模型,两个函数都是参数化的,有助于高效的接口。
当数据包操作发生的窗口给出一个正标志时,检测被认为是True Positive (TP)。同样地,当在包含操作记录的窗口中没有检测到标记时,将认为是False Negative (FN)。相反,False Positive (FP)表示给一个没有操作过数据包的窗口一个正标志,True Negative (TN)表示给这样一个窗口一个负标志。
对分类器性能的分析利用计算:
准确性是指正确分类的反应的比例:
$$
\frac{TP+TN}{TP+FP+TN+FN}
$$
敏感性(或回忆)是发现实际事件的能力:
$$
\frac{TP}{TP+FN}
$$
特异性是指测试对被评估的病情的特异性:
$$
\frac{TN}{FP+TN}
$$
准确性可能会产生误导,因为它掩盖了测试数据集中正元素和负元素的相对比例。如果底层测试集包含大量的否定实例,那么只做出否定响应的分类器可以获得很高的准确率。同样,对于只对包含大量肯定实例的数据集作出肯定响应的分类器也是如此。因此,敏感性和特异性也包括在结果分析中。
V 结果与讨论
测试比较了不同评分阈值(即z分数值、标准化ARIMA残差值和监督方法的绝对时差)下的检出率。这些方法最初是在只包含五个最高优先级CAN id的样本上进行测试的。这些有最高的广播率,很少变化的时间(图1和2)。由于这些是最高优先级,很可能他们也会携带重要信息,使其成为高攻击目标。随后的分析包括了所有的CAN id,并观察了改变分析窗口大小的影响。
A. 高优先级CAN id的结果
表1列出了在对5个最高优先级ID进行分类时,这些方法在最高准确度级别上的得分
表I:调整阈值后,对于5个最高优先级的CAN id,三种方法在最高准确度点的得分
特异性评分和敏感性评分通常在这些准确性上都很高,反映了一个强大的能力,以避免假阴性,并捕捉大多数攻击。然而,在注入模拟中,ARIMA的灵敏度较低,表明其检测单记录注入的能力在这些点上是最弱的。在最高准确度点,ARIMA方法检测了100个注射剂中的93个(灵敏度为0.9300),并正确分类了8845个非注射窗口中的8844个(特异性为0.9999)。
准确性得分很大程度上受测试数据中大量的负面(非攻击)窗口影响。因此,在最高观测精度点时,检测响应可能不是最佳的。图3、图4、图5分别为注射检测、滴注记录检测和两种检测联合检测的灵敏度、特异性和准确性评分。ARIMA方法和Z-score方法的注射检测和滴注记录检测结果相似,表明两种方法对任何一种攻击都具有可比性。当超过最佳阈值时,这些方法的灵敏度迅速下降。相比之下,监督方法的灵敏度保持不变的阈值测试下降记录检测。当然,灵敏度下降的速度取决于所测试阈值的粒度和范围。例如,测试的阈值范围仅为8到10个分数,在图上显示出较平缓的斜率。即便如此,结果表明了正确选择阈值的重要性。
在趋于平稳之前,所有方法的特异性随着阈值的增加而增加。因此,在较高的阈值水平上,积极的反应更有可能是正确的。然而,由于灵敏度下降,这些方法不太可能检测到攻击,因此导致响应数量的下降。本质上,提高阈值可以让更多的正实例逃避检测;但一旦检测出来,就不太可能出错。
如何选择正确的阈值是敏感性和特异性之间的权衡。
受试者工作特征(ROC)曲线显示了不同检测阈值下的真阳性率(或敏感性)对假阳性率(或1-特异性)的影响。曲线越接近左上角,分类器的灵敏度和特异性越好。一个完美的分类器会产生一条直线,直线沿Y轴向上到顶部,然后水平到右边的[25]。我们的分类器的ROC曲线(图6)是相似的,并且曲线接近于左上角,表明它们在最佳阈值率下在这项任务中表现良好。
图7显示了扩展到所有CAN ID的测试的组合数据包丢弃和注射结果(每个测试的结果非常相似,因此没有单独显示)。这些方法在攻击检测方面仍然显示出一定的成功,但是容量减少了(图8)。特别是,ARIMA评分法和Z评分法的敏感性在比较阈值时有所降低,因此这些方法做出积极回应的可能性相应降低。监督方法在较低的阈值下显示出比其稍低的特异性
这些结果可能反映了许多较低优先级的标识具有较不稳定的广播间隔范围,因此增加了方差;无人监管的方法适应了这种情况,导致他们做出的决策成比例地减少。相比之下,监督方法的固定方差假设确保了它在不考虑数据方差的情况下继续做出相似比例的决策;这些决定变得不那么正确。因此,在测试的中间阈值,监督方法得到了12377个肯定回答,其中17%是正确的,而ARIMA方法只得到1229个肯定回答,其中25%是正确的,而Z评分方法得到了429个肯定回答,其中71%是正确的。
增加窗口大小也被研究(图9)。保持窗口大小小可能是首选,因为它将最小化攻击检测延迟。在阈值保持不变的情况下,增加窗口大小对特异性和准确性影响不大,但确实增加了ARIMA和Z-score方法的灵敏度。这反映了真阳性和假阳性的增加,因此,假设假阳性是要避免的,可能没有什么好处。
、
该研究使用一个时间定义的窗口来检测注射和刷新攻击导致的CAN活动的变化,这可能成为一个越来越大的威胁。分析了三种方法,将窗口内CAN包的每个广播间隔与窗口内具有相同ID的所有包的平均间隔进行比较。这减少了对平均值的计算,因为它们只在每个窗口的末尾计算,而不是在每个包广播时重新计算平均值的移动窗口。
具有高优先级、频繁广播CAN id的非监督方法(ARIMA和Z-score),不需要对数据集进行事先分析,其性能可与监督方法相比,后者需要事先分析以确定合适的阈值参数。当所有CAN id均纳入分析时,检测精度降低。当包含优先级较低、更不稳定的CAN id时,两种无监督方法受到的影响最大。不过,可以调整一些参数和因素来优化性能,特别是使用ARIMA时,因此进一步的研究可能会提高性能。
研究还强调了确保最佳阈值的重要性。尤其当该值设置过高时,检测方法的灵敏度迅速下降,而当该值设置过低时,特异性下降。尽管如此,本文研究的方法值得进一步研究,以便将其纳入CAN网络安全系统。虽然有监督的方法可以提供更好的结果,但这取决于对目标系统的配置。非监督方法(如ARIMA和Z-score)提供的解决方案可能较少依赖于对特定CAN的分析。
还研究了增加窗口大小(图9)。保持窗口大小较小可能是首选,因为这将最小化攻击检测延迟。在阈值保持不变的情况下,增加窗口大小对特异性和准确性影响不大,但确实增加了ARIMA和Z评分法的敏感性。这反映了真阳性和假阳性的增加,因此假设要避免假阳性可能没有什么好处。
与任何检测系统一样,知道它是如何运行的,可能会鼓励攻击者试图欺骗或绕过它。例如,通过了解现有的广播速率和分析窗口模式,攻击者可能会试图以与窗口边界和窗口内构建规则模式的速率对应的突发方式注入包,以欺骗系统。为每个窗口大小分配一个随机参数可以看作是一种措施。然而,由于系统总是从前一个广播计算时间间隔,即使该广播发生在前一个窗口,它也不太可能被这样的谨慎的定时攻击,尽管这种攻击可能与错误的窗口有关。
这项研究着眼于使用一个时间定义的窗口来检测由注射和再冲击攻击引起的CAN活动的变化,这种攻击可能会成为一种越来越大的威胁汽车变得更加自主和互联。分析了三种方法,将该窗口内的每个局域网数据包的广播间隔与该窗口内具有相同标识的所有数据包的平均值进行比较。这减少了平均值的计算,因为这些仅在每个窗口结束时计算,而不是在每个分组广播时重新计算平均值的移动窗口。
无监督方法(ARIMA和Z评分)具有高优先级、频繁广播的控制器局域网标识,不需要对数据集进行预先分析,其性能与有监督方法相当,有监督方法需要进行预先分析来确定合适的阈值参数。当所有的CAN ID都包括在分析中时,检测精度降低。当包含优先级较低、更不稳定的广播CAN ID时,这两种无监督方法受到的影响最大。不过,有一些参数和因素可以调整以优化性能,尤其是在ARIMA,因此进一步的研究可能会提高性能。
研究还强调了确保最佳阈值的重要性。特别是,如果设置得太高,检测方法的灵敏度会迅速下降,而如果设置得太低,特异性会降低。然而,这里研究的方法值得进一步研究,以纳入一个局域网网络安全系统。虽然有监督的方法可以给出更好的结果,但这取决于它是为目标系统配置的。无监督方法(如ARIMA和Z-score)提供的解决方案可能不太依赖于对特定CAN的分析。
与任何检测系统一样,对其运行方式的了解可能会鼓励攻击者试图欺骗或规避它。例如,在已知现有广播速率和分析窗口模式的情况下,攻击者可能会试图以对应于窗口边界的突发形式注入数据包,并以在窗口内构建规则模式的速率注入数据包,以试图欺骗系统。给每个窗口大小分配一个随机参数可能被认为是一种反措施。但是,由于系统总是计算前一次广播的时间间隔,即使该广播发生在前一个窗口中,也不太可能被这种精心安排的攻击所欺骗,尽管该攻击可能与错误的窗口相关联。
未来工作
这项研究着眼于一辆车的数据,以及有限的驾驶可能性。进一步的调查将涉及更广泛的车辆和行程类型。我们测试了两种类型的攻击,仅限于注入单个记录和短时间内丢弃记录。调查进一步的攻击,例如跨越多个窗口的攻击,或者以不同的速率注入记录,可能会导致这些方法产生不同的检测模式。就检测率而言,需要探索数据包的特征。虽然我们将最高优先级数据包的结果与完整数据包的结果进行了比较,但我们尚未量化数据包特征和检测性能之间的关系。更清楚地了解这些可能会更好地告知特定电子控制单元检测方法的适用性。还需要调查其他车辆的广播模式和最佳阈值。
虽然我们的研究只关注了时间上的变化,但我们承认,攻击模式的设计可能不会在网络数据包的时间或频率上产生明显的差异。例如,frschle和sth ring[12]概述了静默攻击,然后模拟电子控制单元,而不会在消息模式中留下任何痕迹。泰勒等人也考虑了类似的攻击。基于时间的入侵检测无法检测到此类攻击,这表明需要内置的安全措施,如强大的访问控制和消息身份验证,以及可以确定有效负载差异的检测方法,这也是我们正在探索的一个方面。
我们也认识到,防止袭击很重要,特别是对再次袭击这样的袭击,这种袭击一旦发生可能很难应对。然而,在这里,一些攻击之前可能会有其他具有可检测的广播速率变化的攻击,例如获取系统信息的模糊攻击。显然,这里需要更多的研究,包括检测和响应。
我们的攻击模拟是通过直接修改捕获的数据文件生成的。这意味着,即使攻击会导致局域网改变其后续行为,在我们的模拟中也不会观察到数据的下游变化。这是一个更具挑战性的限制,因为我们不能对行驶中的汽车进行攻击。一种可能性是使用一个测试平台来创建数据,如福勒等人[27]提出的。这将提供更真实的数据,因为数据中会捕捉到连锁效应;例如,一个更高优先级的标识的频率变化引起的一个局域网标识频率的变化。虽然对没有备用汽车和测试轨道的研究人员来说,产生实际的攻击是有问题的,但是可以模拟局域网,例如使用专有软件和接口硬件。